
本文是 Future3 Campus AI+Web3 产业研究报告第二篇,详解基础设施层的发展潜力、叙事逻辑和代表性头部项目。

原文作者:Future3 Campus
原文来源:万向区块链
本文是 Future3 Campus AI+Web3 产业研究报告第二篇,详解基础设施层的发展潜力、叙事逻辑和代表性头部项目。第一篇:AI+Web3 未来发展之路(一):产业图景和叙事逻辑。
基础设施是 AI 发展的确定性成长方向
爆发增长的 AI 算力需求
近年来,算力需求快速增长,尤其是在 LLM 大模型面世后,AI 算力需求引爆了高性能算力市场。OpenAI 数据显示,自 2012 年以来,用于训练最大 AI 模型的计算用量呈指数级增长,平均每 3-4 个月翻倍,其增长速度大大超过了摩尔定律。AI 应用的需求增长导致了对计算硬件的需求快速增加,预计到 2025 年,AI 应用对计算硬件的需求将增长约 10% 到 15%。
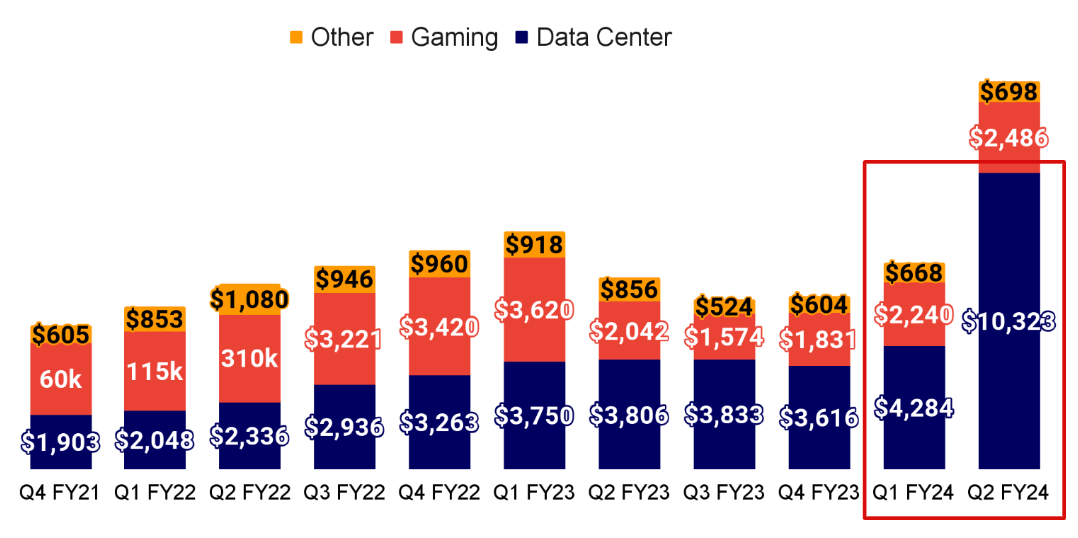
受 AI 算力需求影响,GPU 硬件厂商英伟达的数据中心收入持续增长,23 年 Q2 的数据中心收入达到 $10.32B,比 23 年 Q1 增长 141%,比去年同期增长 171%。2024 财年第四季度中数据中心业务占据 83% 以上营收,同步增长 409%,其中 40% 用于大模型的推理场景,显示出对于高性能算力的强大需求。
同时需要海量数据也对存储和硬件内存提出了要求,尤其是在模型训练阶段,需要大量的参数输入,需要存储大量数据。在 AI 服务器中应用的存储芯片主要包括:高带宽存储器 (HBM)、DRAM 和 SSD,针对 AI 服务器的工作场景需要提供更大的容量、更高的性能、更低的延迟和更高的响应速度。根据美光测算, AI 服务器中 DRAM 数量是传统服务器的 8 倍,NAND 是传统的 3 倍。
供需失衡推动高昂的算力成本
通常来说,算力主要应用在 AI 模型的训练、微调和推测阶段,尤其是在训练微调阶段,由于更大的数据参数输入和计算量,同时对并行计算的互联性要求更高,因此需要更性能、互联能力更强的 GPU 硬件,通常是高性能的 GPU 算力集群。随着大模型的发展,计算复杂度也直线上升,使得需要更多高端硬件来满足模型训练需求。
以 GPT3 为例,按 1300 万独立用户访问的情况来说,对应的芯片需求是 3 万多片 A100GPU。那么初始投入成本将达到惊人的 8 亿美元,每日模型推理费用预估费用 70 万美元。
同时,据行业报道,2023 年第四季度,NVIDIA GPU 供应量在全球范围内都被严格限制,导致全球市场都出现了明显的供不应求。英伟达产能受限于台积电、HBM、CoWos 封装等产能,H100 的「严重缺货问题」至少会持续到 2024 年底。
因此高端 GPU 的需求上升和供应受阻两方面推动了当前 GPU 等硬件的高昂价格,尤其是类似英伟达这种占据产业链底层核心的公司,通过龙头垄断还能进一步获得价值红利。例如英伟达的 H100 AI 加速卡的物料成本约为 3000 美元,而在 2023 年中售价已经达到了 3.5 万美元左右,甚至在 eBay 上卖出了超过 4w 美元的价格。
AI 基础设施占据产业链核心价值增长
Grand View Research 的报告显示,全球云 AI 市场的规模在 2023 年估计为 626.3 亿美元,并预计到 2030 年将增长到 6476 亿美元,年复合增长率为 39.6%。这一数据反映了云 AI 服务的增长潜力及其在整个 AI 产业链中所占的重要份额。
根据 a16z 的估算,AIGC 市场的大量资金最终流向了基础设施公司。平均而言,应用程序公司将大约 20-40% 的收入用于推理和针对每个客户的微调。这通常直接支付给计算实例的云提供商或第三方模型提供商——反过来,第三方模型提供商将大约一半的收入花在云基础设施上。因此,有理由猜测当今 AIGC 总收入的 10-20% 流向了云提供商。
同时,更大一部分的算力需求在于大型 AI 模型的训练,例如各类 LLM 大模型,尤其是对于模型初创公司,80-90% 的成本都用于 AI 算力使用。综合来看,AI 计算基础设施(包括云计算和硬件)预计占据市场初期 50% 以上的价值。
去中心化 AI 计算
如上文所述,当前中心化 AI 计算的成本高企,很重要的一个原因是 AI 训练对高性能基础设施的需求增长。但是实际上市场上大量仍然存在大量的算力面临闲置的问题,出现了一部分的供需错配。其中主要原因是:
- 受限于内存,模型复杂度与所需要的 GPU 数量并不是线性增长关系:当前的 GPU 具有算力优势,但是模型训练需要大量的参数存储在内存。例如对于 GPT-3 来说,为了训练 1750 亿个参数的模型,需要在内存中保存超过 1 TB 的数据——这超过了当今现有的任何 GPU,因此需要更多的 GPU 进行并行计算和存储,这又会导致 GPU 算力的闲置。比如从 GPT3 到 GPT4,模型参数规模增加约 10 倍,但是所需要的 GPU 数量增加了 24 倍(且不考虑模型训练时间的增长)。据相关分析称,OpenAI 在 GPT-4 的训练中使用了大约 2.15e25 的 FLOPS,在大约 25000 个 A100 GPU 上进行了 90 到 100 天的训练,其算力利用率约为 32% 至 36%。
面对以上问题,设计更加符合 AI 工作的高性能芯片或者专用 ASIC 芯片是目前很多开发者和大型企业在探索的方向,另一个角度则是综合利用现有的计算资源,建设分布式算力网络,通过算力的租赁、共享、调度等来降低算力的成本。此外,目前市场有很多闲置的消费级 GPU 和 CPU,单体算力不强,但是在某些场景或者与现有高性能芯片一起配置也能过满足现有的计算需求,最重要的是供应充足,通过分布式网络调度能够进一步降低成本。
因此分布式算力成为了 AI 基础设施发展的一个方向。同时因为 Web3 与分布式具有相似的概念,去中心化算力网络也是当前 Web3+AI 基础设施的主要应用方向。目前市场上的 Web3 去中心化算力平台普遍能够提供相比较中心化云算力低 80%-90% 的价格。
存储虽然也为 AI 最重要的基础设施,但存储对大规模、易用性、低延迟等要求使得目前中心化的存储具有更大的优势。而分布式计算网络由于其显著的成本优势,则存在更加切实的市场,能够更大地享受到 AI 市场爆发带来的红利。
- 模型推理和小模型训练是当前分布式算力的核心场景。分布式算力由于算力资源的分散,不可避免地增加 GPU 之间的通信问题,因此会降低算力性能。因此,分布式算力首先更加适合对通信要求少,可以支持并行的场景,例如 AI 大模型的推理阶段,以及参数量比较少的小模型,其受到的性能影响较小。事实上随着未来 AI 应用的发展,推理才是应用层的核心需求,大部分公司没有能力去做大模型的训练,因此分布式算力仍然具有长期潜力的市场。
- 为大规模并行计算设计的高性能分布式训练框架也不断涌现。例如 Pytorch、Ray、DeepSpeed 等创新式的开源分布式计算框架为开发者使用分布式算力进行模型训练提供了更强的基础支持,使得分布式算力在未来 AI 市场的适用性会更强。
AI+Web3 基础设施项目的叙事逻辑
我们看到,分布式 AI 基础设施需求强,且具有长期增长潜力,因此是易于叙事和受到资本青睐的领域。目前 AI+Web3 产业的基础设施层的主要项目基本是以去中心化的计算网络为主要的叙事,以低成本为主要优势,以代币激励为主要方式扩展网络,服务 AI+Web3 客户为主要目标。主要包括两个层面:
1.比较纯粹的去中心化云计算资源的共享和租赁平台:有很多早期的 AI 项目,例如 Render Network、Akash Network 等;
- 算力资源为主要竞争优势:核心竞争优势和资源通常是能够接触到大量的算力提供商,快速建立其基础网络,同时提供易用性强的产品给客户使用。早期市场中很多做云算力的公司和矿工会更容易切入这个赛道。
- 产品门槛较低,上线速度快:对于 Render Network、Akash Network 这种成熟产品来说,已经可以看到切实增长的数据,具有一定的领先优势。
- 新进入者产品同质化:由于目前赛道热点和此类产品低门槛的特点,最近也进入了一大批做共享算力、算力租赁等叙事的项目,但是产品比较同质化,还需要看到更多的差异化竞争优势。
- 偏向于服务简单计算需求的客户:例如 Render Network 主要服务渲染需求,Akash Nerwork 的资源提供中 CPU 更多。简单的计算资源租赁多数满足简单的 AI 任务需求,无法满足复杂的 AI 训练、微调、推测等全生命周期需求。
2.提供去中心化计算 +ML 工作流服务:有很多最近获得高额融资的新兴项目,例如 Gensyn, io.net, Ritual 等;
- 去中心化计算抬高估值地基。由于算力是 AI 发展的确定性叙事,因此具有算力基础的项目通常具有更加稳定和高潜力的商业模式,使得对比纯中间层项目具有更高的估值。
- 中间层服务打出差异化优势。中间层的服务则是这些算力基础设施具有竞争优势的部分,例如服务 AI 链上链下计算同步的预言机和验证器,服务 AI 整体工作流的部署和管理工具等。AI 工作流具有协作性、持续反馈、复杂度高等特点,在流程中的多个环节都需要应用到算力,因此一个更加具有易用性,高协作性,能够满足 AI 开发者复杂需求的中间层基础设施在当下是具有竞争力的,特别是在 Web3 领域中需要满足 Web3 开发者对于 AI 的需求。这样的服务更容易承接到潜在的 AI 应用市场,而不是仅仅支持简单的计算需求。
- 通常需要在 ML 领域有专业运维经验的项目团队。能够提供上述中间层服务的团队通常需要对整个 ML 的工作流程有详细的了解,才能更好的满足开发者的全生命周期需求。尽管这类的服务通常会采用到很多现有的开源框架和工具,不一定具有强技术创新,但是仍然需要具有丰富经验和强大工程能力的团队,这也是项目的竞争优势。
通过提供比中心化云计算服务更优惠的价格,但配套和使用体验比较相近的服务,这类项目获得了很多头部资本的认可,但同时技术复杂度也更高,目前基本在叙事和开发阶段,还未有完善上线的产品。
代表项目
Render Network
Render Network 是一个基于区块链的全球渲染平台,提供分布式的 GPU,为创作者提供更低成本,更高速的 3D 渲染服务,在创作者确认过渲染结果后,再由区块链网络向节点发送代币奖励。平台提供分布式 GPU 的调度和分配网络,按照节点的用量情况、声誉等进行作业的分配,最大化地提高计算的效率,减少资源闲置,降低成本。
Render Network 的代币 RNDR 是平台中的支付型代币,创作者可以使用 RNDR 支付渲染服务,服务商则通过提供算力完成渲染作业而获得 RNDR 奖励。渲染服务的价格会根据当前网络中的用量情况等进行动态调节。
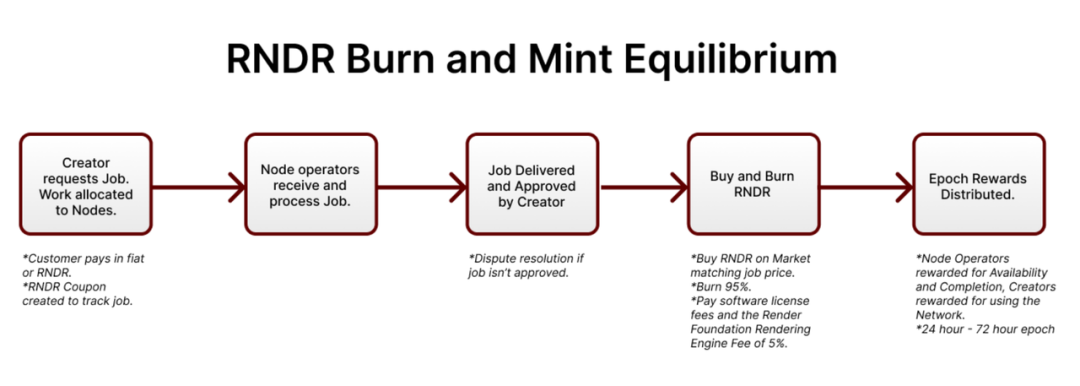
渲染是分布式算力架构运用相对合适且成熟的场景,因为可以将渲染任务分为多个子任务高度并行地执行,互相之前不需要过多的通信和交互,所以可以最大化避免分布式算力架构的弊端,同时充分利用广泛的 GPU 节点网络,有效降低成本。
因此,Render Network 的用户需求也较为可观,自 2017 年创立以来,Render Network 用户在网络上渲染了超过 1600 万帧和近 50 万个场景,且渲染帧数作业和活跃节点数都呈增长的趋势。此外,Render Network 于 2023 Q1 也推出了原生集成 Stability AI 工具集,用户可以的该项功能引入 Stable Diffusion 作业,业务也不再局限于渲染作业而向 AI 领域扩展。
Gensyn.ai
Gensyn 是一个用于深度学习计算的全球性的超级计算集群网络,基于波卡的 L1 协议,2023 年获得了由 a16z 领投的 4300 万美元 A 轮融资。
Gensyn 的叙事架构中不仅包含了基础设施的分布式算力集群,还包括上层的验证体系,证明在链外执行的大规模计算是按照链的要求执行的,即用区块链来验证,从而构建一个无需信任的机器学习网络。
分布式算力方面,Gensyn 能够支持从多余容量的数据中心到带有潜在 GPU 的个人笔记本电脑,它将这些设备连接成一个单一的虚拟集群,开发者可以随需访问和点对点使用。Gensyn 将创建一个价格由市场动态决定且向所有参与者开放的市场,可以使 ML 计算的单位成本达到公平均衡。
而验证体系是 Gensyn 更重要的概念,它希望网络能够验证机器学习任务是否按照请求正确完成,它创新了一种更加高效的验证方法,包含了概率性学习证明、基于图的精准定位协议和 Truebit 式激励游戏三大核心技术点,相比传统区块链中的重复验证方法更加高效。其网络中的参与者包括提交者、求解者、验证者和举报者,来完成整个验证流程。
按照 Gensyn 协议在白皮书中的综合测试数据来看,目前其显著优势是:
- 能够降低 AI 模型训练的成本:预计 Gensyn 协议上的 NVIDIA V100 等效计算的每小时成本约为 0.40 美元,比 AWS 按需计算便宜 80%。
- 更加高效的无需信任的验证网络:按照白皮书中的测试,Gensyn 协议进行模型训练的时间开销,与 Truebit 式复制相比,性能提升了 1,350%,与以太坊相比,性能提升了 2,522,477%。
但同时,分布式算力相比较本地训练,由于通讯和网络问题,不可避免地增加了训练时间,测试数据中,Gensyn 协议为模型训练增加了约 46% 的时间开销。
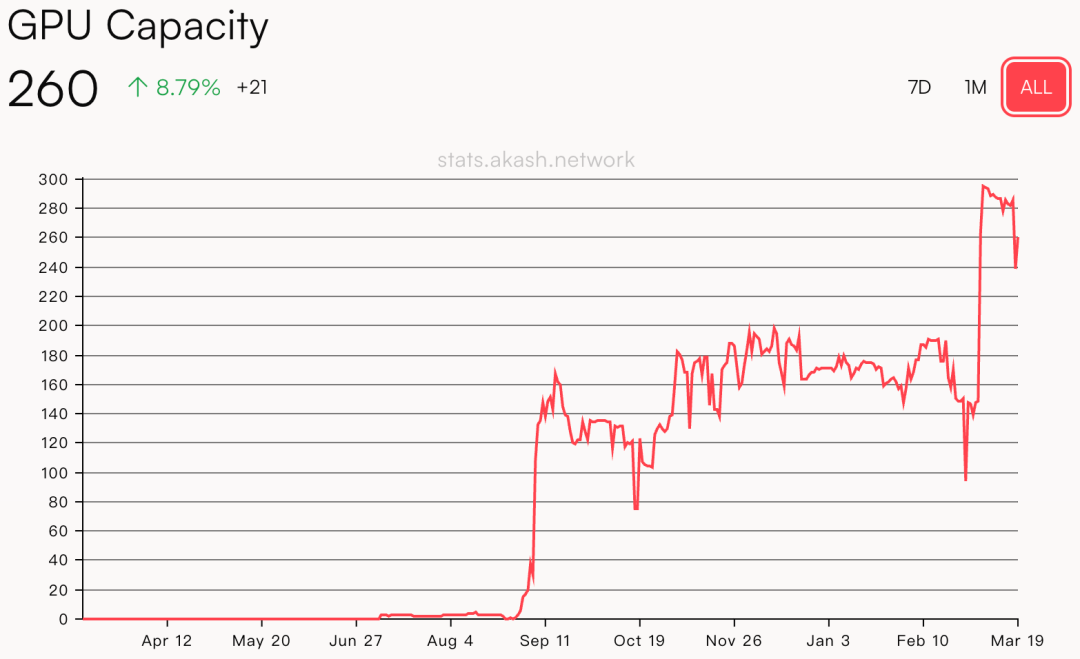
Akash network
Akash network 是一个分布式的云计算平台,结合不同的技术组件,让用户可以在去中心化的云环境中高效、灵活地部署和管理应用程序,简单地说,它提供用户租赁分布式计算资源。
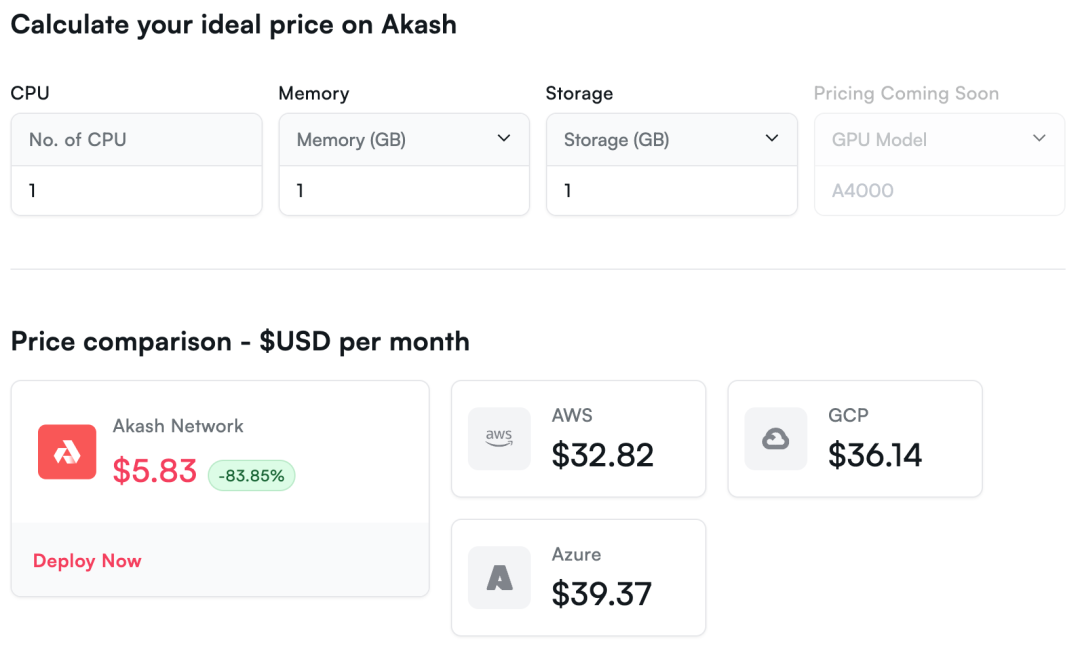
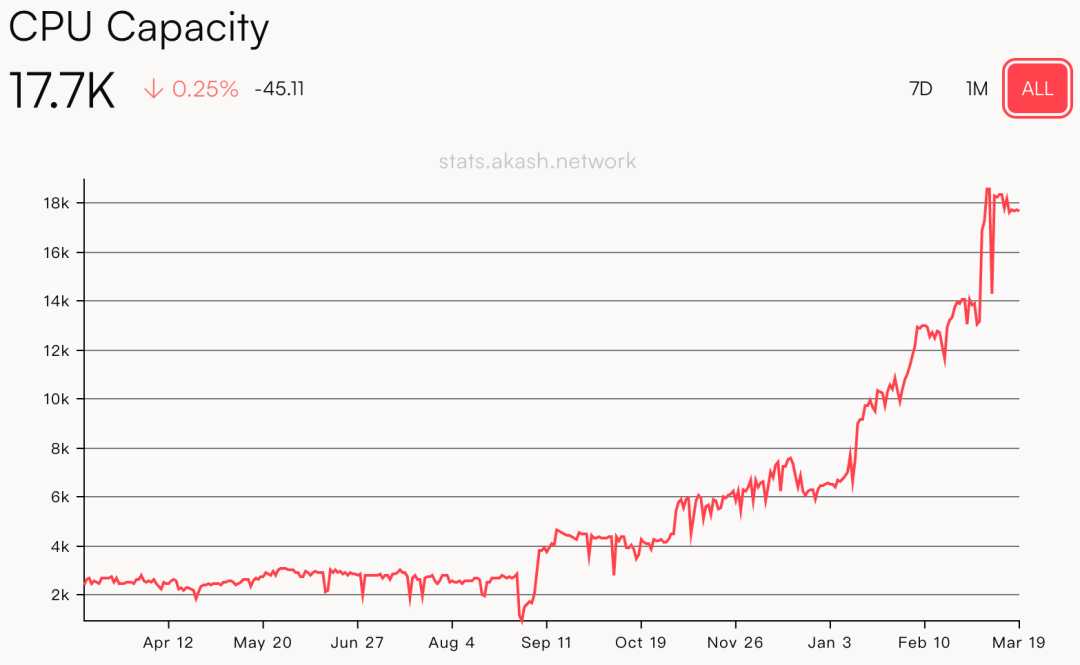
Akash 的底层是分布在全球的多个基础设施服务商,提供 CPU、GPU、内存、存储资源,并通过上层的 Kubernetes 集群将资源提供给用户进行租赁。而用户可以将应用程序部署为 Docker 容器,来使用更低成本的基础设施服务。同时,Akash 采用「反向拍卖」的方式,使得资源价格进一步降低。按照 Akash 官网的估算,其平台的服务成本比中心化服务器降低约 80% 以上。
io.net
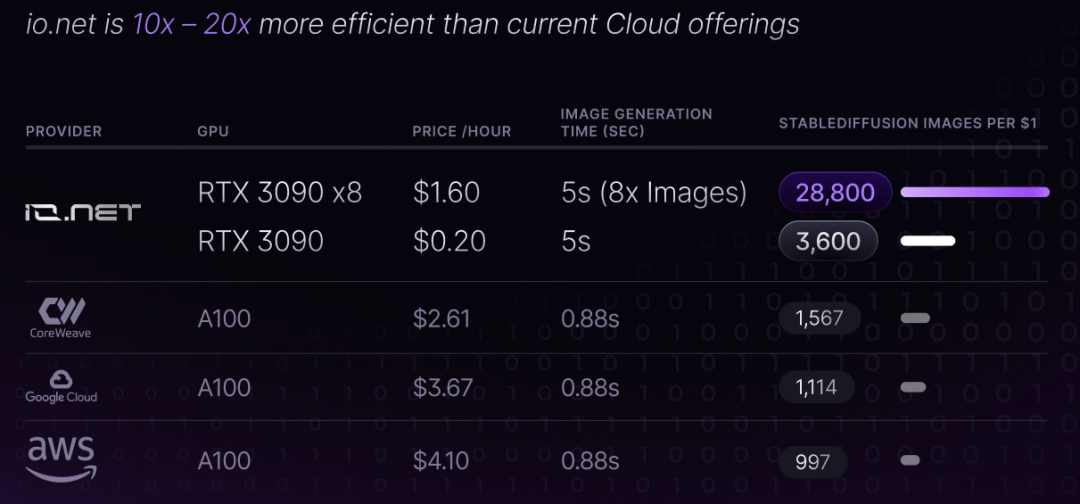
io.net 是一个去中心化计算网络,连接全球分布式的 GPU,为 AI 的模型训练和推理等提供算力支持。io.net 刚刚完成了 3000 万美元的 A 轮融资,估值达到了 10 亿美元。
io.net 相比 Render、Akash 等,是一个更加健全、扩展性更强的去中心化计算网络,接入多个层面的开发者工具,其特点包括:
- 聚合更多的算力资源:独立数据中心、加密矿工以及 Filecoin、Render 等加密项目的 GPU。
- 核心支持 AI 需求:核心服务的功能包括批量推理和模型服务、并行训练、并行超参数调整和强化学习。
- 更加健全的技术栈以支持更高效的云环境工作流:包括多种编排工具、ML 框架(计算资源的分配、算法的执行以及模型训练和推理等操作)、数据存储解决方案、GPU 监控和管理工具等。
- 并行计算能力:集成 Ray 这一开源的分布式计算框架,拥抱 Ray 的原生并行性,轻松并行化 Python 函数,从而实现动态任务执行。其内存存储确保任务之间的快速数据共享,消除序列化延迟。此外,io.net 不仅限于 Python,还集成了 PyTorch 和 TensorFlow 等其他领先的 ML 框架,使其扩展性更强。
在价格上,io.net 官网预计其价格将比中心化云计算服务降低约 90%。
此外,io.net 的代币 IO coin 未来主要用于生态内服务的支付和奖励,或者需求方也可以用类似 Helium 的模式将 IO coin 燃烧换成稳定币「IOSD 积分」来进行支付。
本文来自万向区块链,经授权后发布,本文观点不代表星空财经BlockGlobe立场,转载请联系原作者。

相关推荐
-
对话慢雾:Web3安全现状、应对策略与创业前景
-
Kaia基金会主席详解「Kaia+LINE NEXT」如何塑造Kaia未来生态
-
德鼎创新基金合伙人王岳华:RWA、DePIN、AI有明显破圈属性,AI创业公司机会在于专业领域数据壁垒
-
对话 Tangent 联创:流动性基金 vs 风险投资,谁在真正推动加密市场
-
山寨之王,为何陷入四面楚歌?
-
「数字财富」南亚小国——比特币大国
-
为什么你要关注比特币的OP_CAT?闪电网络后的最大叙事
-
Kyle Samani Token2049演讲:为什么Solana将超越以太坊
-
特朗普受访全文:美国环境对加密货币非常敌对 SEC 正在严厉打击
-
靴子落地!美联储降息,比特币大牛市要开启了吗?
-
NFT 化的社交互动:与其点赞,不如铸造
-
TOKEN2049 透视:数字货币重塑经济权力
